Presented at: Setting Global Standards for Granular Data: Sharing the Challenge - Frankfurt, 28-29th March 2017 - hosted by the OFR, ECB and BOE
Why was the goal of our project to clearly specify and communicate a set of words and enable those works to be turned directly into actions? The answer lies in scale.
If you can get your business users to directly contribute to your development of business rules for regulation, standards, or data requirements, in a structured, executable and scalable way, then the reliance on technical experts stops becoming a bottleneck. You gain the scale of a larger group.
This project was NOT yet another rules engine, rules language, electronic format or ontology project, this project was about using an open architecture to gain the benefits of the aforementioned but importantly about gaining the additional clarity by showing how those words result in actions.
The Challenge
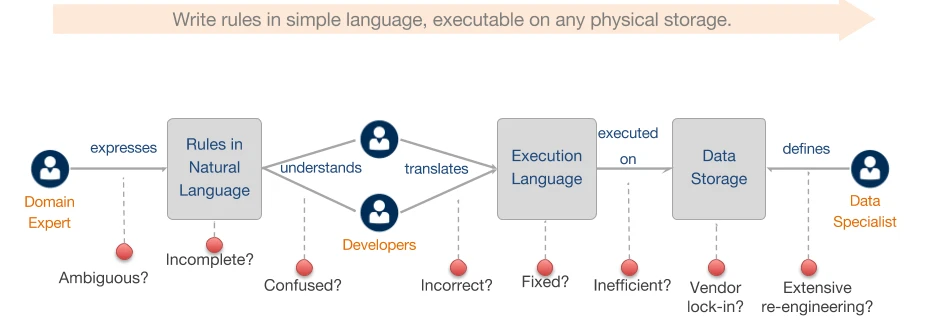
We want to emancipate the business users to enable them to express the rules they want without having to learn technologies.
Domain expert writing rules:
- Unsure if the rules are complete and free of overlap and contradiction.
- Extensive manual review is required.
- User is free to express any rule without specialist training or tools.
Developer:
- Unsure if the implementation is correct or consistent with the specification.
- Must become a bit of a domain expert to interpret and implement the rules.
- Testing and code reviews required.
Execution:
- Is the implementation optimal? As part of the project we experimented with running poorly written rules and the outcome was a 60x slowdown in speed!
- Execution is highly dependent on the skills and style of the developer, and knowledge can be lost if that developer moves on.
- If one wishes to change execution platforms all of the rules must be manually recorded.
Storage:
Is the data storage optimal (e.g. indexes) to serve the queries efficiently?
- What happens to rules if the schema changes? Which rules are affected?
- What happens when the database technology changes? Extensive re-engineering effort.
- Resistance too, or significant cost involved in change (technology / vendor lock-in).
THE GOAL
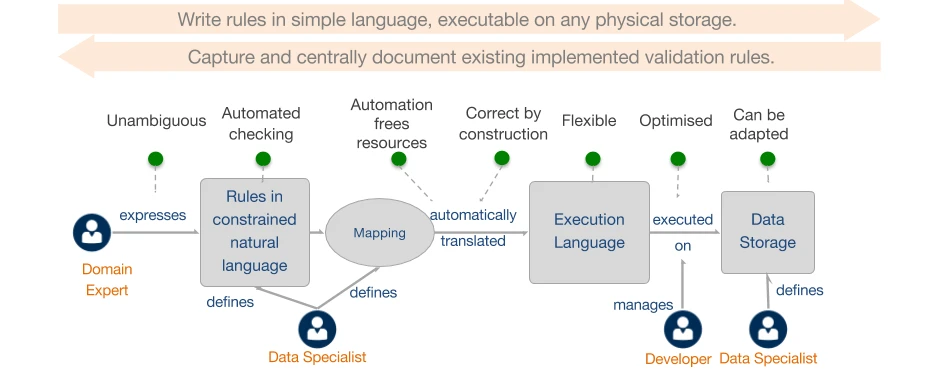
Domain expert writing rules:
- Can be checked automatically (model checkers, theorem provers).
- Could take effort to define and learn, but the benefit of using a relevant business vocabulary means it is relevant to the user, reducing the learning curve to author rules.
- Some constraints cannot be specified (fine if < 5%).
We demonstrated several types of mappings (see below) in the project:
- FORMATTING: e.g. ‘Name’ and ‘Birth date’ mapped to ‘Name, Birth date’.
- RENAMING: e.g. ‘Blacklisted’ mapped to ‘Banned’.
- FORMULA: e.g. ‘Current Balance’ mapped to ‘Opening Balance + Changes in Balance’.
- CONCATENATIONS: e.g. ‘Address’ mapped to ‘House Number, Road, Town, City’.
Developer:
- Moves repetition from people to machines – frees up resources.
- Correct by construction.
- Challenging to implement, particularly mapping.
Execution:
- Automatically optimised by the transformation (machines are much better / consistent at this).
- Development team is fully in control of the optimisation and execution.
- Error reporting is relevant since based on the business vocabulary.
Storage:
- Can adapt. Update the transformation and re-generate executable rules.
- Rules can be maintained centrally but executed against a federation of different repositories.
WHY READABLE, EXECUTABLE RULES?
With clear, natural language rules domain experts can contribute to development, providing scale.
For example, with natural language rules a complex statement in XBRL like the following
<generic: link xlink:type="extended" xlink:role="https://www.xbrl.org/2003/role/link">
<va:valueAssertion xlink:type="resource" xlink:label="assertion" id="assertion" test="$netIncomes le $grossIncomes"/>
<variable:factVariable xlink:type="resource" xlink:label="GrossIncomes" bindAsSeqence="false"/>
<variable:factVariable xlink:type="resource" xlink:label="NetIncomes" bindAsSeqence="false"/>
<variable:variableArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2008/variable-set" xlink:from="assertioon" xlink:to="GrossIncomes" order="1.0" name="grossIncomes"/>
<variable:variableArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2008/variable-set" xlink:from="assertioon" xlink:to="GrossIncomes" order="2.0" name="netIncomes"/>
<cf:conceptName xlink:type="resource" xlink:label="GrossIncomesFilter">
<cf:concept>
<cf:qname> concept:GrossIncomes </cf:qname>
</cf:concept>
</cf:conceptName>
<cf:conceptName xlink:type="resource" xlink:label="NetIncomesFilter">
<cf:concept>
<cf:qname> concept:NetIncomes </cf:qname>
</cf:concept>
</cf:conceptName>
<variable:variableFilterArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2008/variable-filter" xlink:from="GrossIncomes" xlink:to="GrossIncomesFilter" complement="false" cover="true" order="1.0"/>
<variable:variableFilterArc xlink:type="arc" xlink:arcrole="http://xbrl.org/arcrole/2008/variable-filter" xlink:from="NetIncomes" xlink:to="NetIncomesFilter" complement="false" cover="true" order="1.0"/>
</generic:>
… simply becomes
Net Incomes Must Be Less Than Or Equal To Gross Incomes
FUTURE WORK
| Task | Example Benefits |
|---|---|
| Additional back-ends | Community contributed range of adapters |
| Query distribution and optimisation | Performance |
| Machine learning | Discover rules and relations |
| Hybrid / augmented intelligence | Incorporate regulations |
| Automated analysis | Check completeness, overlaps or contradictions. Semantic inference. |
| Reverse engineer rules | Documentation, central source. |
| Expand syntax | Regulation, process, semantics, bot automation / smart contracts. |
| Business development environment | Scale and control |
Support for additional back-ends:
- E.g. Big-data platforms (Hadoop/Pig).
- Cultivated by an open architecture on which data adapters can be built, including compilers, interpreters and drivers.
Query distribution and optimisation:
- Be able to spread out queries across a number of repositories.
- Build in optimisations to query generations and continue to be able to improve performance without having to rewrite original rules.
Machine learning of rules from data:
- E.g. In most rows, column C seems to be holding a value very close to the sum of columns A and B.
- E.g. In most rows, when column A is a negative number, the value of column B is “High”.
Hybrid/augmented intelligence:
- Enable domain experts to point machine learning algorithms towards interesting data subsets / classes of data relationships.
- Use machine learning to merge in existing vocabularies – e.g. terms defined in regulations.
Automated analysis and reasoning:
- Incomplete rule-sets (areas of the data not covered by rules).
- Overlapping and contradictory rules.
- Semantic inference to support querying.
Reverse engineer rules:
- Implement rules into constrained English.
- Documentation giving future ability to migrate to a different platform.
- Regulatory rules into constrained English. Provides documentation, process instructions or training materials – e.g. XBRL formulas to Natural Language.
Expand natural language syntax (rules logic) and vocabularies:
- Work with any modular vocabulary set: e.g. FIBO Foundations defines ‘Equity’, IFRS defines ‘Issued Capital’.
- Extend rules logic beyond data validation – e.g. regulations, process rules, data flows, semantics logic (e.g. SWRL).
- Be able to write automation scripts such as smart contracts or process bots.
- Best done by a community of contributors.
Interactive Development Environment for business users and data mapping:
- Examine the best user interfaces that help domain experts write natural language rules.
- Development of a data mapping user interface.
- Building scale by enabling business users to directly contribute to development, but gain control by structuring the contribution and incorporating software development best practices and tools – e.g. analysis of code completion, testing.